

ディープラーニングの未来は、これら3つの学習パラダイムに分解できます。

ディープラーニングの未来は、これら3つの学習パラダイムに分解できます。
ハイブリッド、複合、および削減された学習
元のウェブサイト:
ディープラーニングは広大な分野であり、その形状は数百万または数十億もの変数によって決定され、絶えず変更されているアルゴリズム、つまりニューラルネットワークを中心としています。一日おきに圧倒的な量の新しい方法や技術が提案されているようです。
ただし、一般的に、現代の深層学習は3つの基本的な学習パラダイムに分類できます。それぞれの中には、ディープラーニングの現在の力と範囲を拡大するための大きな可能性と関心を提供する学習へのアプローチと信念があります。
ハイブリッド学習 —現代の深層学習手法は、教師あり学習と教師なし学習の境界を越えて、大量の未使用のラベルなしデータに対応するにはどうすればよいでしょうか。
複合学習 —さまざまなモデルやコンポーネントを創造的な方法で接続して、パーツの合計よりも大きい複合モデルを作成するにはどうすればよいでしょうか。
学習の減少 —同じかそれ以上の予測力を維持しながら、パフォーマンスと展開の両方の目的で、モデルのサイズと情報フローの両方をどのように削減できますか?
ディープラーニングの未来は、学習のこれら3つのパラダイムにあり、それぞれが高度に相互接続されています。
ハイブリッド学習
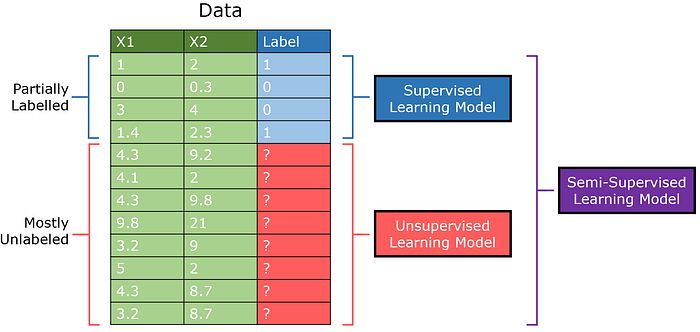
このパラダイムは、教師あり学習と教師なし学習の境界を越えることを目的としています。ラベル付けされたデータが不足していてコストが高いため、ビジネスのコンテキストでよく使用されます。本質的に、ハイブリッド学習は質問への答えです、
教師ありの方法を使用して、教師なしの問題を解決する/一緒に行うにはどうすればよいですか?
1つは、半教師あり学習が機械学習コミュニティで定着しており、ラベル付けされたデータがほとんどない教師あり問題で非常に優れたパフォーマンスを発揮できることです。たとえば、適切に設計された半教師ありGAN(Generative Adversarial Network)は、MNISTデータセットで90%を超える精度を達成しました。 たった25のトレーニング例。
半教師あり学習は、教師なしデータが多数あるが、教師ありデータが少量であるデータセット用に設計されています。従来、教師あり学習モデルはデータの一部でトレーニングされ、教師なしモデルは他の部分でトレーニングされていましたが、半教師ありモデルでは、ラベル付きデータとラベルなしデータから抽出された洞察を組み合わせることができます。
半教師ありGAN(SGANと略記)は、標準の適応です 生成的敵対的ネットワークモデル。弁別器は、画像が生成されたかどうかを示す0/1を出力するだけでなく、アイテムのクラスも出力します(多出力学習)。
これは、識別器が実際の画像と生成された画像を区別することを学習することにより、具体的なラベルなしでそれらの構造を学習できるという考えを前提としています。少量のラベル付きデータからの追加の強化により、半教師ありモデルは、最小限の教師ありデータで最高のパフォーマンスを達成できます。
SGANと半教師あり学習についてもっと読むことができます ここ。
GANは、ハイブリッド学習の別の分野にも関わっています— 自己管理 教師なし問題が教師あり問題として明示的に組み立てられる学習。GANは、ジェネレーターの導入により、監視ありデータを人為的に作成します。ラベルは、実際の/生成された画像を識別するために作成されます。教師なしの前提から、教師ありタスクが作成されました。
または、の使用法を検討してください エンコーダー-デコーダーモデル 圧縮用。最も単純な形式では、それらは、ある種のボトルネックの圧縮された形式を表すために、中央に少量のノードを持つニューラルネットワークです。両側の2つのセクションは、エンコーダーとデコーダーです。
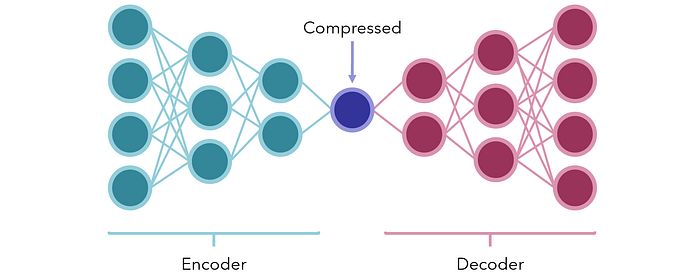
ネットワークは、 同じ ベクトル入力として出力します(教師なしデータから人為的に作成された教師ありタスク)。意図的に中央にボトルネックが配置されているため、ネットワークは情報を受動的に渡すことはできません。代わりに、入力の内容を小さなユニットに保存して、デコーダーによって再度合理的にデコードできるようにするための最良の方法を見つける必要があります。
トレーニング後、エンコーダーとデコーダーは分解され、圧縮またはエンコードされたデータの受信側で使用して、データがほとんどまたはまったく失われることなく、非常に小さな形式で情報を送信できます。また、データの次元を減らすために使用することもできます。
別の例として、テキストの大規模なコレクション(おそらくデジタルプラットフォームからのコメント)を考えてみましょう。いくつかのクラスタリングまたは 多様体学習 この方法では、テキストのコレクションのクラスターラベルを生成し、それらをラベルとして扱うことができます(クラスタリングが適切に行われている場合)。
各クラスターが解釈された後(たとえば、クラスターAは製品について不平を言うコメントを表し、クラスターBは正のフィードバックを表すなど)、次のような深いNLPアーキテクチャー BERT 次に、新しいテキストをこれらのクラスターに分類するために使用できます。これらはすべて、完全にラベル付けされていないデータであり、人間の関与は最小限です。
これもまた、教師なしタスクを教師ありタスクに変換する魅力的なアプリケーションです。すべてのデータの大部分が教師なしデータである時代では、ハイブリッド学習を使用して教師あり学習と教師なし学習の境界を越える創造的な架け橋を構築することには、途方もない価値と可能性があります。
複合学習
複合学習は、1つのモデルではなく、複数のモデルの知識を活用しようとします。静的および動的の両方の情報の独自の組み合わせまたは注入を通じて、ディープラーニングは単一のモデルよりも理解とパフォーマンスを継続的に深めることができると信じられています。
転移学習は複合学習の明らかな例であり、モデルの重みを同様のタスクで事前トレーニングされたモデルから借用し、特定のタスクで微調整できるという考えを前提としています。のような事前訓練されたモデル インセプション またはVGG-16は、いくつかの異なるクラスの画像を区別するように設計されたアーキテクチャとウェイトで構築されています。
動物(猫、犬など)を認識するようにニューラルネットワークをトレーニングする場合、良い結果を得るには時間がかかりすぎるため、畳み込みニューラルネットワークを最初からトレーニングすることはありません。代わりに、画像認識の基本をすでに保存しているInceptionのような事前トレーニング済みモデルを使用して、データセットのいくつかの追加エポックについてトレーニングします。
同様に、NLPニューラルネットワークでの単語の埋め込みは、それらの関係に応じて、埋め込みスペース内の他の単語に物理的に近い単語をマッピングします(たとえば、「apple」と「orange」は「apple」と「truck」よりも距離が短くなります)。GloVeのような事前にトレーニングされた埋め込みをニューラルネットワークに配置して、単語を数値的で意味のあるエンティティにすでに効果的にマッピングしているものから始めることができます。
それほど明白ではありませんが、競争は知識の成長を刺激することもあります。1つは、Generative Adversarial Networksは、基本的に2つのニューラルネットワークを相互に対立させることにより、複合学習パラダイムから借用しています。ジェネレータの目標は、ディスクリミネータをだますことであり、ディスクリミネータの目標はだまされないことです。
モデル間の競争は「敵対的学習」と呼ばれ、他のタイプの敵対的学習と混同しないでください。 悪意のある入力の設計とモデルの弱い決定境界の悪用。
敵対的学習は、通常はさまざまなタイプのモデルを刺激する可能性があり、モデルのパフォーマンスを他のモデルのパフォーマンスと比較して表すことができます。敵対的学習の分野では、まだ多くの研究が行われています。生成的敵対的ネットワークは、サブフィールドの唯一の顕著な創造物です。
一方、競合学習は敵対的学習に似ていますが、ノードごとのスケールで実行されます。ノードは、入力データのサブセットに応答する権利を求めて競合します。競合学習は「競合層」で実装されます。この層では、ランダムに分散された重みを除いて、ニューロンのセットがすべて同じです。
各ニューロンの重みベクトルが入力ベクトルと比較され、類似性が最も高いニューロンである「勝者がすべてを取る」ニューロンがアクティブ化されます(出力= 1)。その他は「非アクティブ化」されています(出力= 0)。この教師なし手法は、 自己組織化マップ と 機能の発見。
複合学習のもう1つの興味深い例は、 ニューラルアーキテクチャ検索。簡単に言えば、強化学習環境のニューラルネットワーク(通常は反復)は、データセットに最適なニューラルネットワークを生成することを学習します—アルゴリズムはあなたに最適なアーキテクチャを見つけます!あなたは理論についてもっと読むことができます ここ およびPythonでの実装 ここ。
アンサンブル手法は、複合学習の定番でもあります。ディープアンサンブル法は非常に優れていることが示されています 効果的、およびエンコーダーやデコーダーのようなモデルのエンドツーエンドのスタックが人気を集めています。
複合学習の多くは、異なるモデル間の接続を構築するための独自の方法を考え出すことです。それは、
単一のモデルは、たとえ非常に大きいものであっても、それぞれがタスクの一部に特化するように委任された、いくつかの小さなモデル/コンポーネントよりもパフォーマンスが低下します。
たとえば、レストランのチャットボットを構築するタスクについて考えてみます。

楽しみ/チャット、情報検索、アクションの3つの部分に分割し、それぞれに特化したモデルを設計することができます。または、単一のモデルを委任して3つのタスクすべてを実行することもできます。
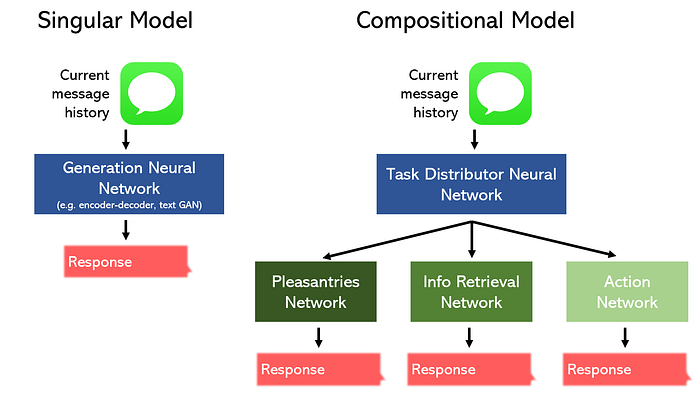
構図モデルがより少ないスペースでより良いパフォーマンスを発揮できるのは当然のことです。さらに、これらの種類の非線形トポロジは、次のようなツールを使用して簡単に構築できます。 Kerasの機能API。
ビデオや3次元データなど、ますます多様化するデータタイプを処理するには、研究者は創造的な構成モデルを構築する必要があります
作文学習と将来についてもっと読む ここ。
学習の減少
モデルのサイズは、特にNLP(深層学習研究における興奮の震源地)で拡大しています。 たくさん。最新のGPT-3モデルには175があります 十億 パラメーター。との比較 BERT 木星を蚊と比較するようなものです(文字通りではありません)。ディープラーニングの未来はもっと大きいですか?
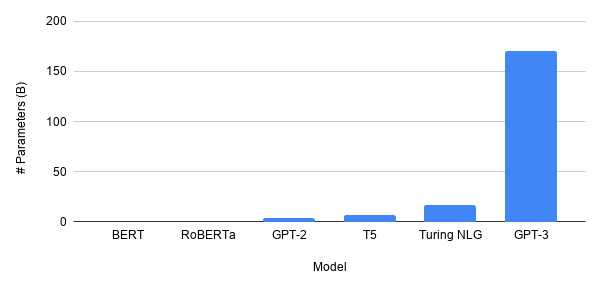
非常に間違いなく、違います。GPT-3は確かに非常に強力ですが、過去に繰り返し、「成功した科学」が人類に最大の影響を与えるものであることを示してきました。学界が現実から離れすぎているときはいつでも、それは通常、曖昧になります。これは、1900年代後半に利用可能なデータが非常に少なかったために、アイデアが独創的であったとしても役に立たなかったために、ニューラルネットワークが短期間忘れられた場合でした。
GPT-3は別の言語モデルであり、説得力のあるテキストを書くことができます。そのアプリケーションはどこにありますか?はい、たとえば、クエリへの回答を生成できます。ただし、これを行うには、より効率的な方法があります(たとえば、知識グラフをトラバースし、BERTなどの小さなモデルを使用して回答を出力します)。
より大きなモデルは言うまでもなく、GPT-3の巨大なサイズが実現可能または必要であるというのは、単にそうではないようです。 枯渇 計算能力の。
「ムーアの法則は、一種の蒸気不足です。」
- サティア・ナデラ、マイクロソフトのCEO
代わりに、スマート冷蔵庫が食料品を自動的に注文し、ドローンが自分で都市全体をナビゲートできるAIが組み込まれた世界に向かっています。強力な機械学習手法をPC、携帯電話、小型チップにダウンロードできる必要があります。
これには軽量AIが必要です。パフォーマンスを維持しながらニューラルネットワークを小さくします。
直接的または間接的に、深層学習研究のほとんどすべてが、必要なパラメーターの量を減らすことに関係していることがわかります。これは、一般化、したがってパフォーマンスの向上と密接に関連しています。たとえば、畳み込み層の導入により、ニューラルネットワークが画像を処理するために必要なパラメーターの数が大幅に削減されました。反復層は、同じ重みを使用しながら時間の概念を組み込んでいるため、ニューラルネットワークはより少ないパラメーターでシーケンスをより適切に処理できます。
埋め込みレイヤーは、追加のパラメーターに負担がかからないように、エンティティを物理的な意味を持つ数値に明示的にマップします。ある解釈では、 脱落 レイヤーは、パラメーターが入力の特定の部分で動作するのを明示的にブロックします。 L1 / L2正則化 ネットワークがすべてのパラメータを利用するようにするために、パラメータが大きくなりすぎないようにし、それぞれが情報の価値を最大化するようにします。
特殊なレイヤーを作成することで、ネットワークはより複雑でより大きなデータに必要なパラメーターをますます少なくします。他のより最近の方法は、明示的にネットワークを圧縮しようとします。
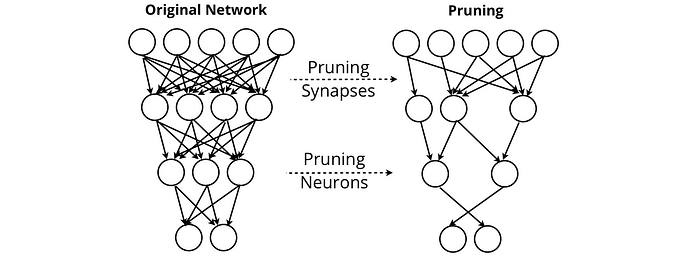
ニューラルネットワークの剪定 ネットワークの出力に価値を提供しないシナプスとニューロンを削除しようとします。剪定により、ネットワークはパフォーマンスを維持しながら、ほとんどすべてを削除できます。
のような他の方法 患者の知識の蒸留 大きな言語モデルを、たとえばユーザーの電話にダウンロード可能なフォームに圧縮する方法を見つけます。これは、 Googleニューラル機械翻訳(GNMT)システム、これは、オフラインでアクセスできる高性能の翻訳サービスを作成する必要があったGoogle翻訳を強化します。
本質的に、削減された学習は、展開中心の設計を中心にしています。これが、学習を減らすためのほとんどの研究が企業の研究部門から行われている理由です。展開中心の設計の1つの側面は、データセットのパフォーマンスメトリックを盲目的に追跡することではなく、モデルが展開されるときに発生する可能性のある問題に焦点を当てることです。
たとえば、前述の 敵対的なインプット ネットワークをだますために設計された悪意のある入力です。標識にスプレーペイントやステッカーを貼ると、自動運転車をだまして制限速度をはるかに超えて加速させることができます。責任ある学習の削減の一部は、モデルを使用するのに十分軽量にするだけでなく、データセットに表されていないコーナーケースに対応できるようにすることです。
「実現可能なアーキテクチャサイズで優れたパフォーマンスを達成できた」というのは、「次のアーキテクチャで最先端のパフォーマンスを達成した」ほどセクシーではないため、ディープラーニングの研究では学習の減少が最も注目されていない可能性があります。何千億ものパラメータの」。
必然的に、高い割合の割合の誇大宣伝された追求がなくなると、示されているようにイノベーションの歴史が示すように、学習の減少(実際には単なる実践的な学習)は、それに値するより多くの注目を集めるでしょう。
概要
ハイブリッド学習は、教師あり学習と教師なし学習の境界を越えようとします。半教師あり学習や自己教師あり学習などの方法では、ラベルのないデータから貴重な洞察を抽出できます。これは、教師なしデータの量が指数関数的に増加するにつれて、非常に価値のあるものになります。
タスクがより複雑になるにつれて、複合学習は1つのタスクをいくつかのより単純なコンポーネントに分解します。これらのコンポーネントが連携して、または相互に作用する場合、結果はより強力なモデルになります。
ディープラーニングが誇大広告の段階を乗り越えるため、学習の削減はあまり注目されていませんが、すぐに十分な実用性と展開中心の設計が登場します。
読んでくれてありがとう!
声明:学術交流のみ。この記事の著作権は原作者に帰属します。何か問題がある場合は、連絡して削除してください。